概述
本章节介绍地平线算法工具链中模型上板推理的快速验证工具,方便开发者可以快速获取到 ***.bin 模型的信息、模型推理的性能、模型debug等内容。
hrt_model_exec 工具使用说明
hrt_model_exec 工具,可以快速在开发板上评测模型的推理性能、获取模型信息等。
目前工具提供了三类功能,如下表所示:
编号 |
子命令 |
说明 |
1 |
|
获取模型信息,如:模型的输入输出信息等。 |
2 |
|
执行模型推理,获取模型推理结果。 |
3 |
|
执行模型性能分析,获取性能分析结果。 |
小技巧
工具也可以通过 -v 或者 --version 命令,查看工具的 dnn 预测库版本号。
例如: hrt_model_exec -v 或 hrt_model_exec –version
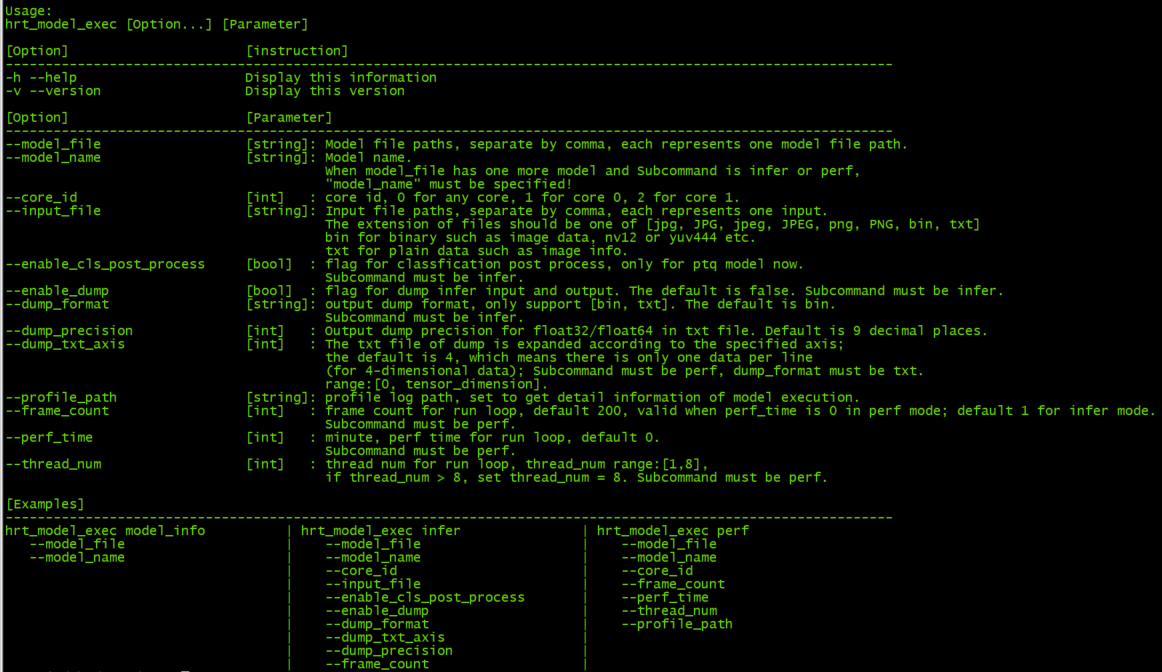
输入参数描述
在开发板上运行 hrt_model_exec 、 hrt_model_exec -h 或 hrt_model_exec --help 获取工具的使用参数详情。
如下图中所示:
编号 |
参数 |
类型 |
说明 |
1 |
|
string |
模型文件路径,多个路径可通过逗号分隔。 |
2 |
|
string |
指定模型中某个模型的名称。 |
3 |
|
int |
指定运行核。 |
4 |
|
string |
模型输入信息,多个可通过逗号分隔。 |
5 |
|
bool |
使能resizer模型推理。 |
6 |
|
string |
指定推理resizer模型时所需的roi区域。 |
7 |
|
int |
执行模型运行帧数。 |
8 |
|
string |
dump模型每一层输入和输出。 |
9 |
|
bool |
使能dump模型输入和输出。 |
10 |
|
int |
控制txt格式输出float型数据的小数点位数。 |
11 |
|
bool |
控制txt格式输出float类型数据。 |
12 |
|
string |
dump模型输入和输出的格式。 |
13 |
|
int |
控制txt格式输入输出的换行规则。 |
14 |
|
bool |
使能分类后处理。 |
15 |
|
int |
执行模型运行时间。 |
16 |
|
int |
指定程序运行线程数。 |
17 |
|
string |
模型性能/调度性能统计数据的保存路径。 |
使用说明
本节介绍 hrt_model_exec 工具的三个子功能的具体使用方法
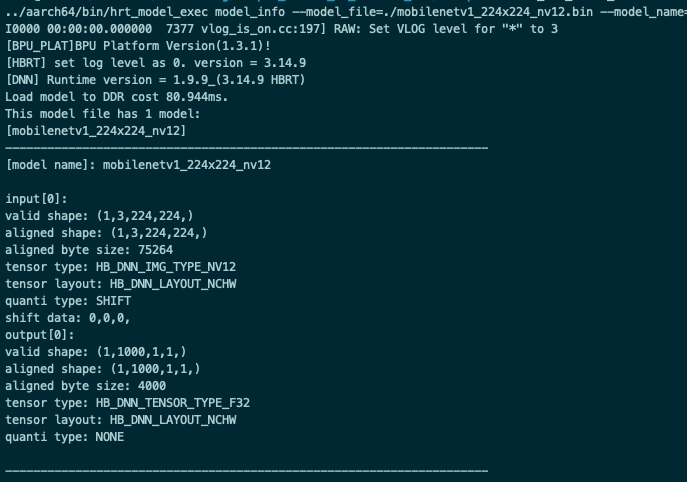
model_info
概述
该参数用于获取模型信息,模型支持范围:QAT模型,PTQ模型。
该参数与 model_file 一起使用,用于获取模型的详细信息;
模型的信息包括:模型输入输出信息 hbDNNTensorProperties 和模型的分段信息 stage ;模型的分段信息是:一张图片可以分多个阶段进行推理,stage信息为[x1, y1, x2, y2],分别为图片推理的左上角和右下角坐标,目前地平线J5的bayes架构支持这类分段模型的推理,x3上模型均为1个stage。
小技巧
不指定 model_name ,则会输出模型中所有模型信息,指定 model_name ,则只输出对应模型的信息。
示例说明
单模型
hrt_model_exec model_info --model_file=xxx.bin
多模型(输出所有模型信息)
hrt_model_exec model_info --model_file=xxx.bin,xxx.bin
多模型–pack模型(输出指定模型信息)
hrt_model_exec model_info --model_file=xxx.bin --model_name=xx
输入参数补充说明
重复输入
若重复指定参数输入,则会发生参数覆盖的情况,例如:获取模型信息时重复指定了两个模型文件,则会取后面指定的参数输入 yyy.bin:
hrt_model_exec model_info --model_file=xxx.bin --model_file=yyy.bin
若重复指定输入时,未加命令行参–model_file,则会取命令行参数后面的值,未加参数的不识别,
例如:下例会忽略 yyy.bin,参数值为 xxx.bin:
hrt_model_exec model_info --model_file=xxx.bin yyy.bin
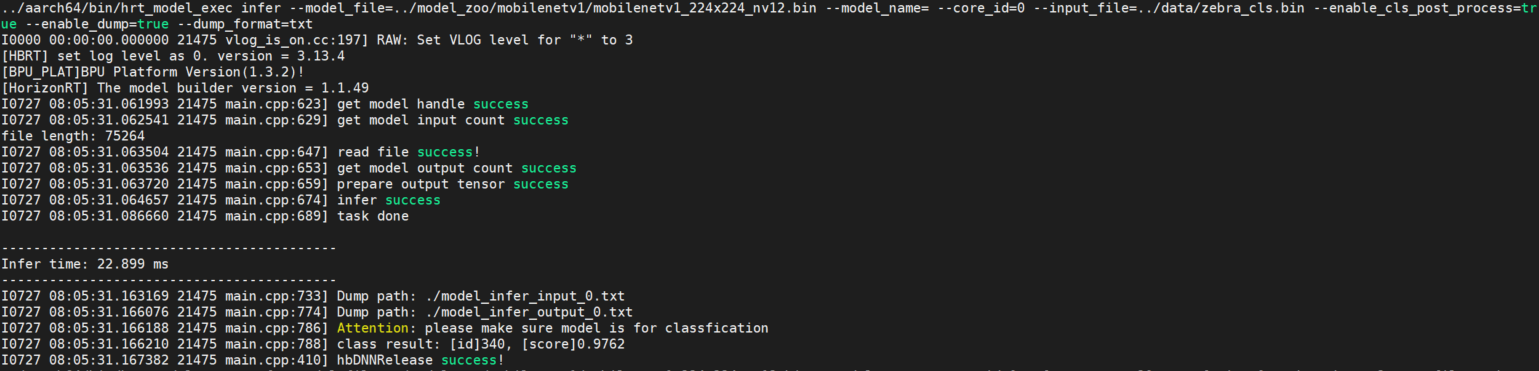
infer
概述
该参数用于输入自定义图片后,模型推理一帧,并给出模型推理结果。
该参数需要与 input_file 一起使用,指定输入图片路径,工具会根据模型信息resize图片。
小技巧
程序单线程运行单帧数据,输出模型运行的时间。
示例说明
单模型
hrt_model_exec infer --model_file=xxx.bin --input_file=xxx.jpg
多模型
hrt_model_exec infer --model_file=xxx.bin,xxx.bin --model_name=xx --input_file=xxx.jpg

可选参数
参数 |
说明 |
|
指定模型推理的核id,0:任意核,1:core0,2:core1;默认为 |
|
使能resizer模型推理;若模型输入包含resizer源,设置为 |
|
|
|
设置 |
|
dump模型每一层输入数据和输出数据,默认值 |
|
dump模型输出数据,默认为 |
|
控制txt格式输出float型数据的小数点位数,默认为 |
|
控制txt格式输出float类型数据,若输出为定点数据将其进行反量化处理,目前只支持四维模型。 |
|
dump模型输出文件的类型,可选参数为 |
|
dump模型txt格式输出的换行规则;若输出维度为n,则参数范围为[0, n], 默认为 |
|
使能分类后处理,目前只支持ptq分类模型,默认 |
多输入模型说明
工具 infer 推理功能支持多输入模型的推理,支持图片输入、二进制文件输入以及文本文件输入,输入数据用逗号隔开。
模型的输入信息可以通过 model_info 进行查看。
示例说明
hrt_model_exec infer --model_file=xxx.bin --input_file=xxx.jpg,input.txt
输入参数补充说明
input_file
图片类型的输入,其文件名后缀必须为 bin / JPG / JPEG / jpg / jpeg 中的一种,feature输入后缀名必须为 bin / txt 中的一种。
每个输入之间需要用英文字符的逗号隔开 ,,例如: xxx.jpg,input.txt。
enable_cls_post_process
使能分类后处理。子命令为 infer 时配合使用,目前只支持在PTQ分类模型的后处理时使用,变量为 true 时打印分类结果。
参见下图:
roi_infer
若模型包含resizer输入源, infer 和 perf 功能都需要设置 roi_infer 为true,并且配置与输入源一一对应的 input_file 和 roi 参数。
如:模型有三个输入,输入源顺序分别为[ddr, resizer, resizer],则推理两组输入数据的命令行如下:
// infer
hrt_model_exec infer --model_file=xxx.bin --input_file="xx0.bin,xx1.jpg,xx2.jpg,xx3.bin,xx4.jpg,xx5.jpg" --roi="2,4,123,125;6,8,111,113;27,46,143,195;16,28,131,183"
// perf
hrt_model_exec perf --model_file=xxx.bin --input_file="xx0.bin,xx1.jpg,xx2.jpg,xx3.bin,xx4.jpg,xx5.jpg" --roi="2,4,123,125;6,8,111,113;27,46,143,195;16,28,131,183"
每个 roi 输入之间需要用英文字符的分号隔开。
dump_intermediate
dump模型每一层节点的输入数据和输出数据。 dump_intermediate=0 时,默认dump功能关闭;
dump_intermediate=1 时,模型中每一层节点输入数据和输出数据以 bin 方式保存,其中 BPU 节点输出为 aligned 数据;
dump_intermediate=2 时,模型中每一层节点输入数据和输出数据以 bin 和 txt 两种方式保存,其中 BPU 节点输出为 aligned 数据;
dump_intermediate=3 时,模型中每一层节点输入数据和输出数据以 bin 和 txt 两种方式保存,其中 BPU 节点输出为 valid 数据。
如: 模型有两个输入,输入源顺序分别为[pyramid, ddr],将模型每一层节点的输入和输出保存为 bin 文件,其中 BPU 节点输出按 aligned 类型保存,则推理命令行如下:
hrt_model_exec infer --model_file=xxx.bin --input_file="xx0.jpg,xx1.bin" --dump_intermediate=1
dump_intermediate 参数支持 infer 和 perf 两种模式。
hybrid_dequantize_process
控制txt格式输出float类型数据。 hybrid_dequantize_process 参数在 enable_dump=true 时生效。
当 enable_dump=true 时,若设置 hybrid_dequantize_process=true ,反量化整型输出数据,将所有输出按float类型保存为 txt 文件,其中模型输出为 valid 数据,支持配置 dump_txt_axis 和 dump_precision;
若设置 hybrid_dequantize_process=false ,直接保存模型输出的 aligned 数据,不做任何处理。
如: 模型有3个输出,输出Tensor数据类型顺序分别为[float,int32,int16], 输出txt格式float类型的 valid 数据, 则推理命令行如下:
// 输出float类型数据
hrt_model_exec infer --model_file=xxx.bin --input_file="xx.bin" --enable_dump=true --hybrid_dequantize_process=true
hybrid_dequantize_process 参数目前只支持四维模型。
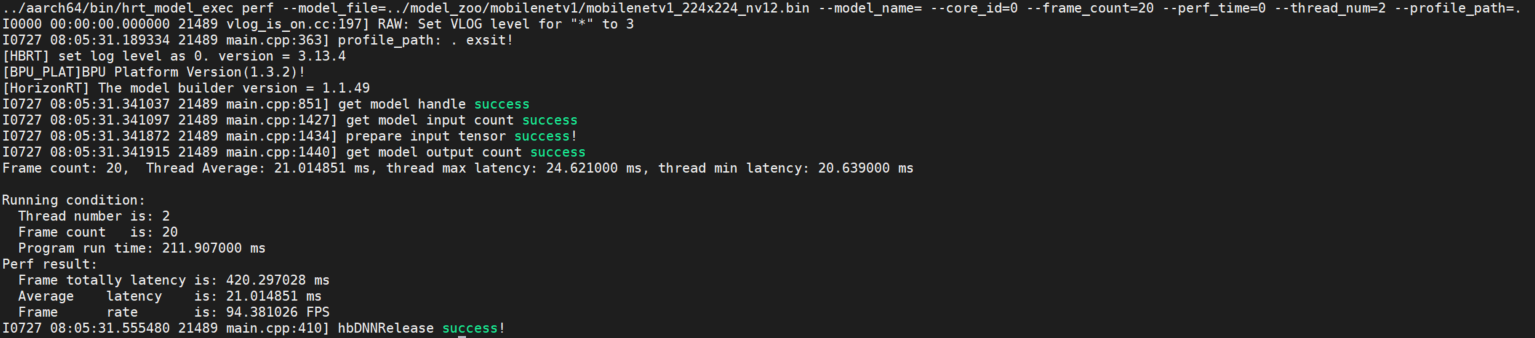
perf
概述
该参数用于测试模型的推理性能。 使用此工具命令,用户无需输入数据,程序会根据模型信息自动构造模型的输入tensor,tensor数据为随机数。 程序默认单线程运行200帧数据,当指定perf_time参数时,frame_count参数失效,程序会执行指定时间后退出。 程序运行完成后,会输出模型运行的程序线程数、帧数、模型推理总时间,模型推理平均latency,帧率信息等。
小技巧
程序每200帧打印一次性能信息:latnecy的最大、最小、平均值,不足200帧程序运行结束打印一次。
示例说明
单模型
hrt_model_exec perf --model_file=xxx.bin
多模型
hrt_model_exec perf --model_file=xxx.bin,xxx.bin --model_name=xx
可选参数
参数 |
说明 |
|
指定模型推理的核id,0:任意核,1:core0,2:core1;默认为 |
|
模型输入信息,多个可通过逗号分隔。 |
|
使能resizer模型推理;若模型输入包含resizer源,设置为 |
|
|
|
设置 |
|
dump模型每一层输入数据和输出数据,默认值 |
|
设置 |
|
设置程序运行线程数,范围[1, 8], 默认为 |
|
统计工具日志产生路径,运行产生profiler.log,分析op耗时和调度耗时。 |
多线程Latency数据说明
多线程的目的是为了充分利用BPU资源,多线程共同处理 frame_count 帧数据或执行perf_time时间,直至数据处理完成/执行时间结束程序结束。
在多线程 perf 过程中可以执行以下命令,实时获取BPU资源占用率情况。
hrut_somstatus -n 10000 –d 1
输出内容如下:
=====================1=====================
temperature-->
CPU : 37.5 (C)
cpu frequency-->
min cur max
cpu0: 240000 1200000 1200000
cpu1: 240000 1200000 1200000
cpu2: 240000 1200000 1200000
cpu3: 240000 1200000 1200000
bpu status information---->
min cur max ratio
bpu0: 400000000 1000000000 1000000000 0
bpu1: 400000000 1000000000 1000000000 0
注解
在 perf 模式下,单线程的latency时间表示模型的实测上板性能,
而多线程的latency数据表示的是每个线程的模型单帧处理时间,其相对于单线程的时间要长,但是多线程的总体处理时间减少,其帧率是提升的。
输入参数补充说明
profile_path
profile日志文件产生目录。
该参数通过设置环境变量 export HB_DNN_PROFILER_LOG_PATH=${path} 查看模型运行过程中OP以及任务调度耗时。
一般设置 --profile_path="." 即可,代表在当前目录下生成日志文件,日志文件为profiler.log。
thread_num
线程数(并行度),数值表示最多有多少个任务在并行处理。 测试延时时,数值需要设置为1,没有资源抢占发生,延时测试更准确。 测试吞吐时,建议设置>2 (BPU核心个数),调整线程数使BPU利用率尽量高,吞吐测试更准确。
// 双核FPS
hrt_model_exec perf --model_file xxx.bin --thread_num 8 --core_id 0
// Latency
hrt_model_exec perf --model_file xxx.bin --thread_num 1 --core_id 1
hrt_bin_dump 工具使用说明
hrt_bin_dump 是 PTQ debug模型的layer dump工具,工具的输出文件为二进制文件。
输入参数描述
编号 |
参数 |
类型 |
描述 |
说明 |
1 |
|
string |
模型文件路径。 |
必须为debug model。即模型的编译参数 |
2 |
|
string |
输入文件路径。 |
模型的输入文件,支持 IMG类型文件需为二进制文件(后缀必须为.bin),二进制文件的大小应与模型的输入信息相匹配, 如:YUV444文件大小为 \(height * width * 3\); TENSOR类型文件需为二进制文件或文本文件(后缀必须为.bin/.txt),二进制文件的大小应与模型的输入信息相匹配, 文本文件的读入数据个数必须大于等于模型要求的输入数据个数,多余的数据会被丢弃; 每个输入之间通过逗号分隔,如:模型有两个输入,则: |
3 |
|
string |
模型卷积层配置文件。 |
模型layer配置文件,配置文件中标明了模型各层信息,在模型编译过程中生成。 文件名称一般为: |
4 |
|
string |
工具输出路径。 |
工具的输出路径,该路径应为合法路径。 |
使用说明
工具提供dump卷积层输出功能,输出文件为二进制文件。
直接运行 hrt_bin_dump 获取工具使用详情。
参见下图:
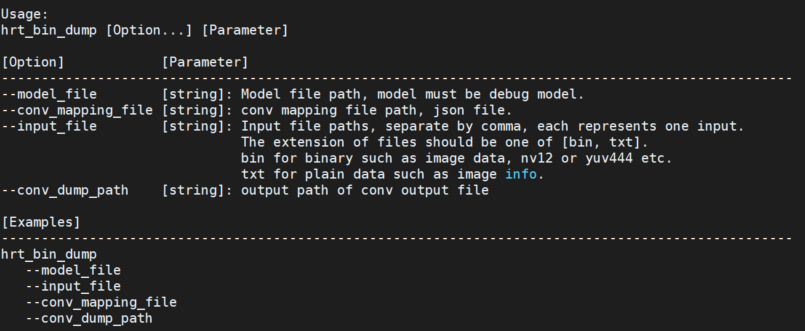
小技巧
工具也可以通过 -v 或者 --version 命令,查看工具的 dnn 预测库版本号。
例如: hrt_bin_dump -v 或 hrt_bin_dump –version
示例说明
以mobilenetv1的debug模型为例,创建outputs文件夹,执行以下命令:
./hrt_bin_dump --model_file=./mobilenetv1_hybrid_horizonrt.bin --conv_mapping_file=./mobilenetv1_quantized_model_conv_output_map.json --conv_dump_path=./outputs --input_file=./zebra_cls.bin
运行日志参见以下截图:

在路径 outputs/ 文件夹下可以查看输出,参见以下截图:
