8.1. 模型性能调优¶
基于前文的性能分析工作,您可能发现性能结果不及预期,本章节内容介绍了地平线对提升模型性能的建议与措施,包括: 检查yaml配置参数、 处理CPU算子、 高性能模型设计建议、 使用地平线平台友好结构&模型 等内容。
注解
检查yaml配置参数、处理CPU算子仅适用于使用 hb_mapper makertbin 进行模型转换编译的使用场景。
部分修改可能会影响原始浮点模型的参数空间,意味着需要您重训模型,为了避免性能调优过程中反复调整并训练的代价, 在得到满意性能效果前,建议您使用随机参数导出模型来验证性能即可。
8.1.1. 检查影响模型性能的yaml参数¶
在模型转换的yaml配置文件中,部分参数会实际影响模型的最终性能,可以先检查下是否已正确按照预期配置, 各参数的具体含义和作用请参考 配置文件具体参数信息 小节的内容。
layer_out_dump:指定模型转换过程中是否输出模型的中间结果,一般仅用于调试功能。 如果将其配置为True,则会为每个卷积算子增加一个反量化输出节点,它会显著的降低模型上板后的性能。 所以在性能评测时,务必要将该参数配置为False。compile_mode:该参数用于选择模型编译时的优化方向为带宽还是时延,关注性能时请配置为latency。optimize_level:该参数用于选择编译器的优化等级,实际生产中应配置为O3获取最佳性能。max_time_per_fc:该参数用于控制编译后的模型数据指令的function-call的执行时长,从而实现模型优先级抢占功能。 设置此参数更改被抢占模型的function-call执行时长会影响该模型的上板性能。
8.1.2. 处理CPU算子¶
如果根据hrt_model_exec perf的评估,确认了突出的性能瓶颈是由于当前算子在CPU上运行导致的。 那么此种情况下,我们建议您先查看 工具链算子支持约束列表 章节,确认当前运行在CPU上的算子是否具备BPU支持的能力。
如果所使用的算子参数超出了BPU支持的约束范围,建议先将原始浮点模型计算参数调整到BPU约束范围内。 为了方便您快速知晓超出约束的具体参数,建议您再使用 验证模型 部分介绍的方法做一遍检查, 工具将会直接给出超出BPU支持范围的参数提示。
注解
修改原始浮点模型参数对模型计算精度的影响需要您自己把控,
例如Convolution的 input_channel 或 output_channel 超出范围就是一种较典型的情况,
减少channel快速使得该算子被BPU支持,单单只做这一处修改也预计会对模型精度产生影响。
如果算子并不具备BPU支持能力,就需要您根据以下情况做出对应优化操作:
CPU算子处于模型中部
对于CPU算子处于模型中部的情况,建议您优先尝试参数调整、算子替换或修改模型。
CPU算子处于模型首尾部
对于CPU算子处于模型首尾部的情况,请参考以下示例,下面以量化/反量化节点为例:
对于与模型输入输出相连的节点,可以在yaml文件model_parameters配置组(模型参数组)中增加
remove_node_type参数,并重新编译模型。remove_node_type: "Quantize; Dequantize"
或使用hb_model_modifier工具对bin模型进行修改:
hb_model_modifier x.bin -a Quantize -a Dequantize
对于下图这种没有与输入输出节点相连的模型,则需要使用hb_model_modifier工具判断相连节点是否支持删除后按照顺序逐个进行删除。
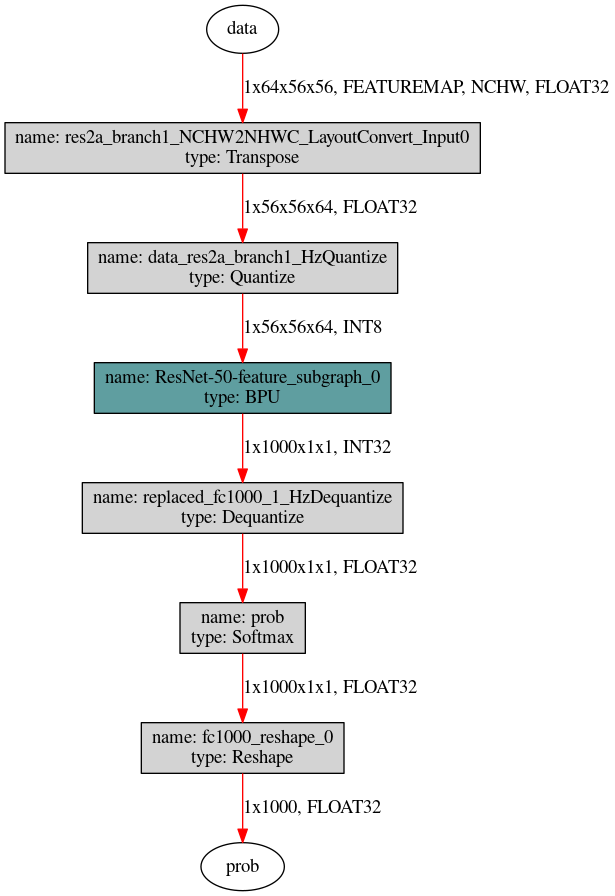
先使用hb_perf工具获取模型结构图片,然后使用以下两条命令可以自上而下移除Quantize节点, 对于Dequantize节点自下而上逐个删除即可,每一步可删除节点的名称可以通过
hb_model_modifier x.bin进行查看。hb_model_modifier x.bin -r res2a_branch1_NCHW2NHWC_LayoutConvert_Input0 hb_model_modifier x_modified.bin -r data_res2a_branch1_HzQuantize
8.1.3. 高性能模型设计建议¶
根据性能评估结果,CPU上耗时占比可能很小,主要的性能瓶颈还是BPU推理时间过长。 这种情况下,我们已经把计算器件都用上了,发力的空间就在于提升计算资源的利用率。 每种处理器都有自己的硬件特性,算法模型的计算参数是否很好地符合了硬件特性, 直接决定了计算资源的利用率,符合度越高则利用率越高,反之则低。 本部分介绍重点在于阐明地平线的硬件特性。 首先,地平线的计算平台旨在加速CNN(卷积神经网络),主要的计算资源都集中在处理各种卷积计算。 所以,我们希望您的模型是以卷积计算为主的模型,卷积之外的算子都会导致计算资源的利用率降低,不同OP的影响程度会有所不同。
另外,在模型设计时,我们应尽量让模型BPU段的输入输出维度降低,以减少量化、反量化节点的耗时和硬件的带宽压力。 以典型的分割模型为例,我们可以将Argmax算子直接合入模型本身。 但需注意,只有满足以下条件,Argmax才支持BPU加速:
Caffe中的Softmax层默认axis=1,而ArgMax层则默认axis=0,算子替换时要保持axis的一致。
Argmax的Channel需小于等于64,否则只能在CPU上计算。
8.1.4. BPU面向高效率模型优化¶
学术界在持续优化算法模型的计算效率(同样算法精度下所需的理论计算量越小越高效)、参数效率(同样算法精度下所用参数量越小越高效)。 这方面的代表工作有EfficientNet和ResNeXt,二者分别使用了Depthwise Convolution和Group Convolution。 面对这样的高效率模型,GPU/TPU支持效率很低,不能充分发挥算法效果,学术界被迫针对GPU/TPU分别优化了EfficientNet V2/X和NFNet, 优化过程主要是通过减少Depthwise Convolution的使用以及大幅扩大Group Convolution中的Group大小, 这些调整都降低了原本模型的计算效率和参数效率。
更多高效模型设计指导建议可参考 高效模型设计指导 章节内容。
同时,我们也提供了丰富的模型给您作为直接的参考,这些产出将不定时更新至https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master,
部分模型源码也放置在OpenExplorer包的 ddk/samples/ai_toolchain/horizon_model_train_sample 路径下,
算法包使用说明可参考 Horizon Torch Samples 章节说明。